Deploy Local Large Language Models with Ollama via Docker and One-API
Ollama is an open-source tool that allows users to conveniently run various large open-source models locally, including ChatGLM from Tsinghua University, Qwen from Alibaba, and Llama from Meta. Currently, Ollama is compatible with three major operating systems: macOS, Linux, and Windows. This article introduces how to install Ollama using Docker, deploy it to use local large models, and integrate it with One-API to easily call large language models via API interfaces.

Hardware Configuration
Since large models have very high hardware requirements, the higher the machine configuration, the better. A dedicated graphics card is recommended, with a minimum of 32GB RAM. The author deployed this on a dedicated server with the following configuration:
- CPU: E5-2696 v2
- RAM: 64GB
- Hard Drive: 512GB SSD
- Graphics Card: None
Note: My dedicated server does not have a graphics card, so I had to run it using the CPU.
Installing Ollama with Docker
Ollama now supports Docker installation, which greatly simplifies the deployment difficulty for server users. Here, we use the docker compose tool to run Ollama. First, create a docker-compose.yaml file with the following content:
version: '3'
services:
ollama:
image: ollama/ollama
container_name: ollama
ports:
- "11434:11434"
volumes:
- ./data:/root/.ollama
restart: always
Then run the command docker compose up -d or docker-compose up -d. After running, visit http://IP:11434. If you see the prompt Ollama is running, the installation was successful, as shown in the figure below:
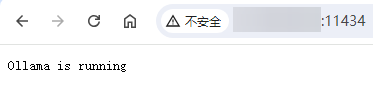
If your machine supports GPU, you can add GPU parameters for support. Refer to: https://hub.docker.com/r/ollama/ollama
Deploying Large Models with Ollama
After installing Ollama, you need to download large models. Supported models can be found on the Ollama official website: https://ollama.com/library. Ollama does not provide a default web interface; you must use the command line. First, enter the container with the following command:
docker exec -it ollama /bin/bash
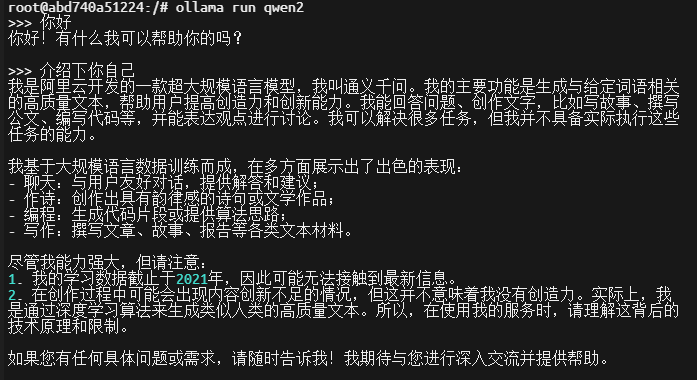
Once inside the container, go to the official website to find the large model you want to download. For example, to download the Alibaba Qwen2 model, use the following command:
ollama run qwen2
After the model is downloaded and running, you can converse via the command line, as shown below:
Common Ollama Commands
Here are some common Ollama commands:
- Run a specific large model:
ollama run llama3:8b-text - List local large models:
ollama list - View running large models:
ollama ps - Delete a specific local large model:
ollama rm llama3:8b-text
Tip: You can also type
ollama -hto view more commands.
Large Model Experience
Currently, the author has downloaded llama2, qwen2, glm4, llama3, and phi3 models for simple usage experience. The following observations may not be entirely rigorous or accurate:
- The
llamamodel is not friendly to Chinese (understandable, as it is a foreign large model). phi3:3.8b, a small model from Microsoft supporting multiple languages, was tested to be quite weak, possibly due to the small number of parameters. It is unknown if upgrading to14bwould improve performance.glm4andqwen2are friendly to Chinese.- Smaller model parameters are weaker; models from
7band above can generally understand and converse normally, while smaller models often make mistakes. - With the above configuration, running a
7bmodel purely on CPU is slightly slow.
Integrating Ollama with One-API
One-API is an open-source AI middleware service that aggregates various large model APIs, such as OpenAI, ChatGLM, and ERNIE Bot. After aggregation, it provides a unified OpenAI calling method. For example, the API calling methods for ChatGLM and ERNIE Bot differ, but One-API can integrate them and provide a unified OpenAI calling method. When calling, you only need to change the model name, eliminating interface differences and reducing development difficulty.
For specific installation methods for One-API, please refer to the official project address: https://github.com/songquanpeng/one-api
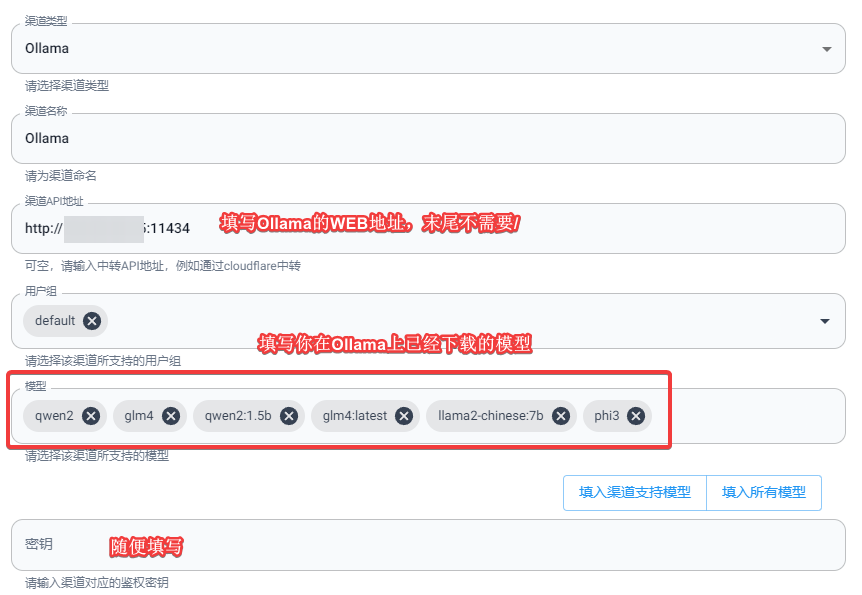
Go to the One-API Backend >> Channels >> Add a new channel.
- Type: Ollama
- Channel API Address: Fill in the Ollama web address, e.g.,
http://IP:11434 - Model: The name of the local large model you have already downloaded on Ollama
- Key: This is a required field. Since Ollama does not default support authentication access, you can fill in any value here.
As shown in the figure below:
After integration, we can request One-API and pass the specific model name for calling testing. The command is as follows:
curl https://ai.xxx.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-xxx" \
-d '{
"model": "qwen2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
- Change
ai.xxx.comto your One-API domain. - Fill in
sk-xxxwith the token you created in One-API.
If the call is successful, it means Ollama has been successfully integrated into One-API.
Issues Encountered
The author attempted to call One-API Ollama using the stream method, but received a blank response. Through issues, it was discovered that this was caused by a One-API bug. Currently, downgrading the One-API version to 0.6.6 resolves the issue. We look forward to the author fixing this problem in the future.
Security Risks
Since Ollama itself does not provide an authentication access mechanism, deploying Ollama on a server poses security risks. Anyone who knows your IP and port can make API calls, which is very insecure. In production environments, we can improve security using the following methods.
Method 1: Linux Built-in Firewall
- When deploying Ollama with Docker, switch to HOST network mode.
- Use the Linux built-in firewall to restrict access to port 11434 only from specified IPs.
Method 2: Nginx Reverse Proxy
- When deploying Ollama with Docker, map the IP to
127.0.0.1. - Then use the local Nginx to reverse proxy
127.0.0.1:11434, and set up blacklists (deny) and whitelists (allow) for IPs on Nginx.
Conclusion
Ollama, as an open-source tool, provides users with a convenient way to deploy and call local large models. Its excellent compatibility and flexibility make running large language models on various operating systems easier. Through Docker installation and deployment, users can quickly get started and flexibly use various large models, providing strong support for development and research. However, since Ollama lacks a built-in authentication access mechanism, users should take appropriate security measures in production environments to prevent potential access risks. Overall, Ollama has great practical value in promoting the application and development of local AI models. If it can improve its authentication mechanism in the future, it will undoubtedly become a powerful assistant for AI developers.
This article partially references:
- Ollama Official Website: https://ollama.com/
- Ollama GitHub Project Address: https://github.com/ollama/ollama
- Ollama Docker Hub: https://hub.docker.com/r/ollama/ollama
- One-API: https://github.com/songquanpeng/one-api